Jaein Land
NLP and others
24 September 2021
[Paper Notes] Fastformer: Additive Attention Can Be All You Need
Chuhan Wu, Fangzhao Wu, Tao Qi, Yongfeng Huang
keywords: Transformer, Attention, Natural Language Processing, Deep Neural Network

요약:
- 저자는 Attention 아키택처의 속도 개선을 위해 논문에서 제안한 additive attention의 linear한 구조로 복잡도를 줄여 속도를 월등히 향상시킴.
- Parameter sharing등 기술을 적용하여 매개변수 사이즈를 줄이는 등 구조적인 요소 외에도 다른 요소로 복잡도를 줄임.
- Attention을 강조한 제목과는 다르게 엄밀히는 Attention 구조라고 하기 애매함.
- Ablation study가 논문에 포함되지 않아, Query, Key, Value 사용의 유용성과 효율성이 검증되었다고 하기 힘듦.
저자는 Transformer의 높은 복잡도를 해결하기 위해 Additive Attention 메커니즘으로 효율적인 연산을 하는 Fastformer을 제안한다. 이 모델에서 Additive Attention은 Global context를 모델링한 후 각 토큰 벡터와 Global context 벡터간의 연산으로 토큰 벡터의 표현을 강화시킨다. 이러한 방식을 통해 Fastformer은 linear complexity만으로 context를 모델링할수 있다. 실험에서는 다섯개의 benchmark dataset으로 다른 task들에 대한 Fastformer의 성능을 검증하는데, 여기에서 task는 semantic classification, topic prediction, news recommendation, 그리고 text summarization을 포함한다. 실험 결과, Fastformer은 많은 Transformer 기반의 모델보다 효율적으로(빠르게) 연산을 할 수 있으면서도 long text의 모델링에서 뒤치지 않는 성능을 보였다.
저자가 밝힌 contributions는 다음과 같다:
- 가장 “효율적”인 Transformer 아키텍처인 Fastformer을 제안;
- Context information을 효율적으로 fully 모델링 할 수 있도록, element-wise product로 global context와 token representations의 연산을 제안;
- 실험에서 Fastformer이 다른 Transformer 모델보다 훨씬 더(much more) 효육적이면서도 뒤지지 않는 성과를 보이는 것을 입증.
Fastformer의 구조를 설명하기에 앞서, 기존 Transformer (이하 standard Transformer)의 구조와 계산 방법을 복습하면 도움이 될 것 같다.
Transformer의 구조는 다음과 같다:
미시적으로 보면 다음과 같다:
주요 연산은 다음처럼 진행된다:
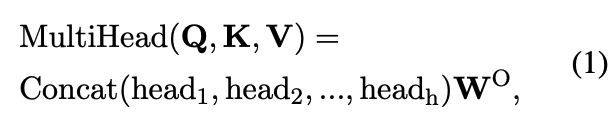
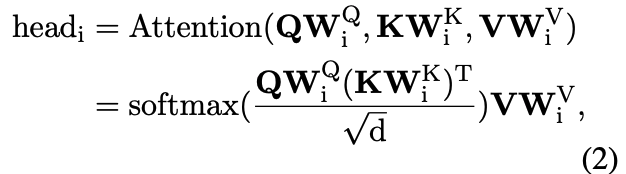
$\mathbf{Q}$, $\mathbf{K}$, $\mathbf{V}$는 각각 key, query, value를 뜻한다. 간단히 이야기하자면, key는 해당 토큰이 무엇인지, query는 이 토큰이 해당 suquence에 있는 다른 토큰들에 대해 무엇을 알고 싶은지, value는 해당 토큰 자체의 정보를 나타낸다. 먼저, $\mathbf{Q}$와 $\mathbf{K}$의 inner product로 하나의 histogram(distribution)을 얻게 되는데, 그는 해당 token에 대한 다른 token들의 중요도를 표현한다고 이해할 수 있다.
Fastformer로 다시 돌아와보면, 우선 Fastformer의 구조는 다음과 같다:
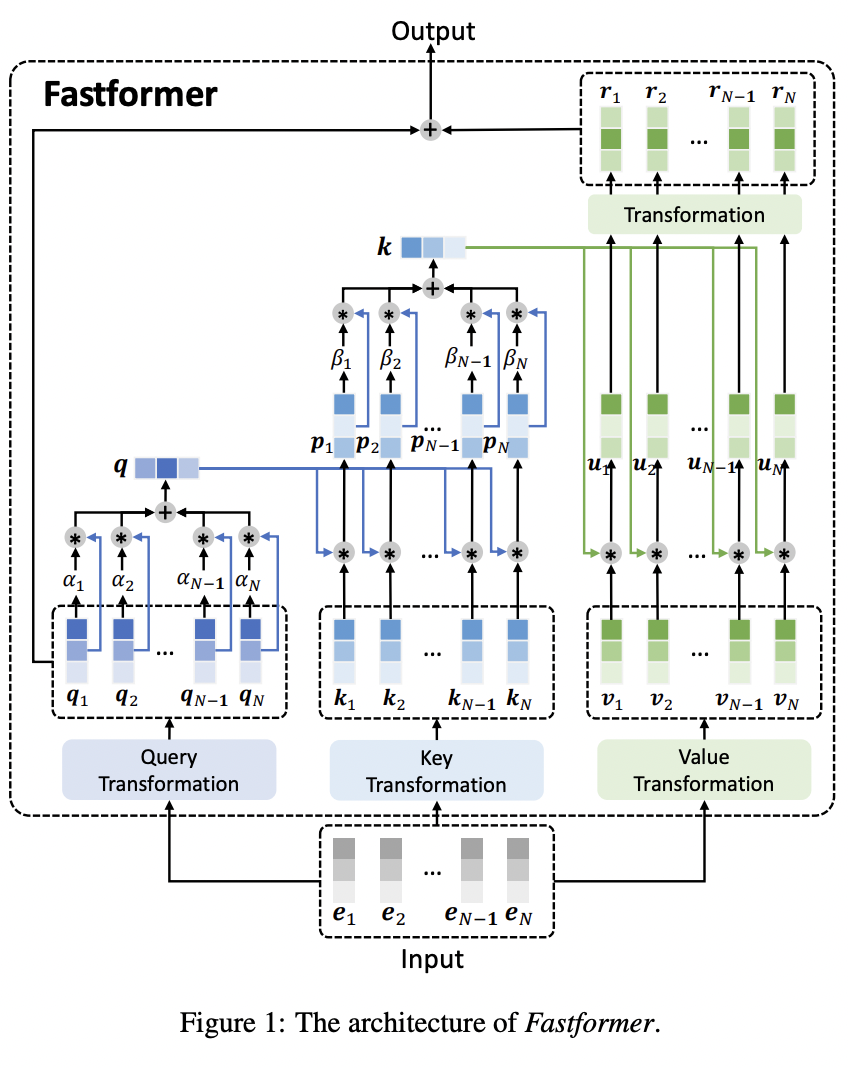
스탠다드 Transformer에서의 Query, Key, Value의 개념은 그대로 가져가고, 구조는 보다시피 매우 복잡하면서도 (Linear한 연산이 대부분이라는 관점에서 관점에서)단순하다. Fastformer에서는 query, key, value의 연산이 독립적으로 진행되는데, 먼저 query matrix를 하나의 global query로 합치고, 이 global query와 global key의 element-wise 연산으로 key matrix를 얻는다. 한개의 global한 vector로 합쳐서 계산을 진행함으로서 계산 복잡도가 줄게되는 것이다.
논문에서는 Fastformer의 아키텍처를 이렇게 묘사했다:
It first uses additive attention mechanism to summarize the query sequence into a global query vector, next models the interaction between the global query vector and attention keys with element-wise product and summarize keys into a global key vector via additive attention, then models the interactions between global key and attention values via elementwise product and uses a linear transformation to learn global context-aware attention values, and finally adds them with the attention query to form the final output.
구체적으로, global query vector은 다음과 같이 계산된다:
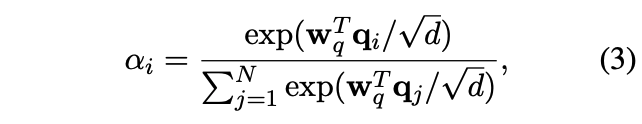
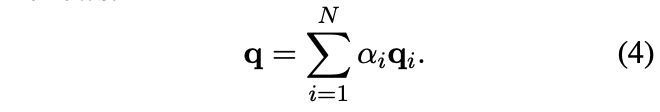
그 다음, global query vector과 각각의 key vector의 element-wise product 연산으로 context-aware한 key matrix를 얻는다. 구체적으로 이 matrix의 i번째 벡터는 $p_i=q*k_i$ 가 된다.
global key vector도 비슷한 방식으로 계산된다:
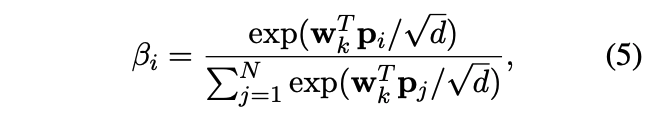
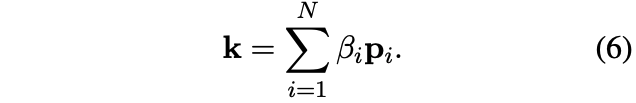
그리고 global key와 value vector의 element-wise product를 연산하여 key-value interection vector을 얻은 후, linear transformation 층을 통해 output matrix $\mathbf{R} = [r_1, r_2, …, r_N] \in \mathbb{R}^{N*d}$를 계산한다. 마지막으로, 이 matrix와 전에 계산했던 query matrix가 더해져 최종 Fastformer의 output이 계산된다. 즉, 기존의 스탠다드 Transformer에서는 각각의 token이 동적으로 정보를 aggregate할 방법을 결정하였다면, Fastformer에서는 token 개별이 아닌 sequence 전체로서의 aggregate 방법을 결정한다.
이러한 방식으로 Fastformer 층들을 쌓게(stacking)되면 contextual information을 모델링 할 수 있다. 또한, 저자는 value와 query transformation parameter에 weight sharing을 적용하여 memory의 cost를 줄이는 시도를 하였다. 뿐만 아니라 각각의 Fastformer 층 사이의 parameter에도 이 방법을 적용하여 parameter 크기도 줄이고 overfitting의 가능성도 줄인다.
복잡도를 보면, query와 key의 additive attention 복잡도는 $O(N\cdot d)$, 파라미터 크기는 $2h\cdot d$가 된다. 여기에서 $h$는 attention head 개수이다. Element-wise product의 시간, 공간 복잡도는 모두 $O(N\cdot d)$로, 총 복잡도는 $O(N\cdot d)^2$가 된다. 이는 스탠다드 Transformer의 복잡도 $O(N^{2d})$에 비해 효율적이다. 실험에서는 IMDB, MIND등 다섯개의 데이터셋으로 Fastformer을 standard Transformer, Longformer, BigBird등 Transformer 기반의 아키텍처와 성능을 비교한다.
여기까지 보면, Transformer을 이해하고 있는 사람들은 자연스럽게 의구심이 생길 수 있는데, 실제로 많은 머신러닝 커뮤니티에 이 논문에 대한 비판이 올라왔다.
몇가지 간단히 적어보자면, 먼저 Attention 연산에서 각 token은 관련있는 다른 token의 정보에 집중하고, 관련 없는 token의 정보는 “필터링”하는 것이 Attention이 수행하는 중요한 일인 데 반해 Fastformer은 단순한 Feedforward 연산에 가까워 보인다. 하여 엄밀히는 이것을 Attention이라고 칭하기 애매 할 수 있다. Transformer의 Query, Key, Value은 명확한 서로 다른 역할을 가진데 반해, Fastformer에서는 크게 다른 점이 없어 보인다. 특히 Query와 Key의 역할이 같다면, Key를 빼버리거나 여러개의 Key를 추가했을 때는 어떻게 될까? 이러한 Ablation Study도 논문에서 포함되지 않았다.
한편, 기존 Query, Key, Value 없이 실험 결과와 같이 SOTA 이상의 결과가 나왔다는 것은 주목할만 하다는 생각이 든다. 아직까지 공개된 코드도 없고, Ablation 실험이 빠진 것 또한 아쉽지만 추후 follow-up paper을 기다려보면 좋겠다.