Jaein Land
NLP and others
15 August 2021
[Paper Notes] Survey of Adversarial Attacks from Accept/Reject Perspectives (1/2)
OpenReview.net에서 리뷰어들의 코멘트와 저자의 답변, 그리고 Accept/Reject 여부를 바탕으로 정리한 Adversarial Attacks 서베이입니다.
All image credits of this post: the original papers.
Papers to explore
This survey covers the following papers including both accepted and rejected papers:
- Towards Robustness Against Natural Language Word Substitutions
- Generating universal language adversarial examples by understanding and enhancing the transferability across neural models
- Neural Attention Distillation: Erasing Backdoor Triggers from Deep Neural Networks
- Robust anomaly detection and backdoor attack detection via differential privacy
- Poisoned classifiers are not only backdoored, they are fundamentally broken
- Clean-Label Backdoor Attacks
- Universal Attacks on Equivariant Networks
- Dynamic Backdoor Attacks Against Deep Neural Networks
- Greedy Attack and Gumbel Attack: Generating Adversarial Examples for Discrete Data
- Just How Toxic is Data Poisoning? A Benchmark for Backdoor and Data Poisoning Attacks
- Fooling a Complete Neural Network Verifier
- Unrestricted Adversarial Attacks For Semantic Segmentation -Black-Box Adversarial Attack with Transferable Model-based Embedding
- BREAKING CERTIFIED DEFENSES: SEMANTIC ADVERSARIAL EXAMPLES WITH SPOOFED ROBUSTNESS CERTIFICATES
- SemanticAdv: Generating Adversarial Examples via Attribute-Conditional Image Editing
- Pragmatic Evaluation of Adversarial Examples in Natural Language
- BadNL: Backdoor Attacks Against NLP Models
Part of the papers are surveyed in this post. The next post will cover the remains.
(More papers may be added)
1. Towards Robustness Against Natural Language Word Substitutions
ICLR 2021 Spotlight
Xinshuai Dong, Anh Tuan Luu, Rongrong Ji, Hong Liu
The Idea: The proposed method ASCC(Adversarial Sparse Convex Combination) captures adversarial word substitutions in the vector space using a convex hull towards robustness. Using a convex hull can satisfy three aspects: inclusiveness, exclusiveness, and optimization.
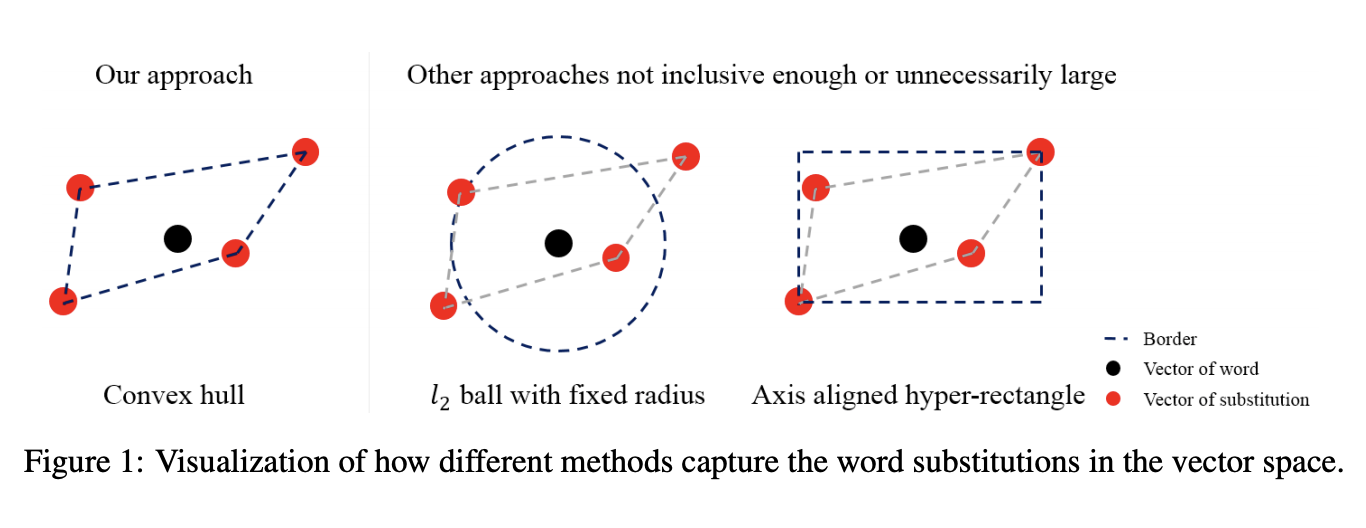
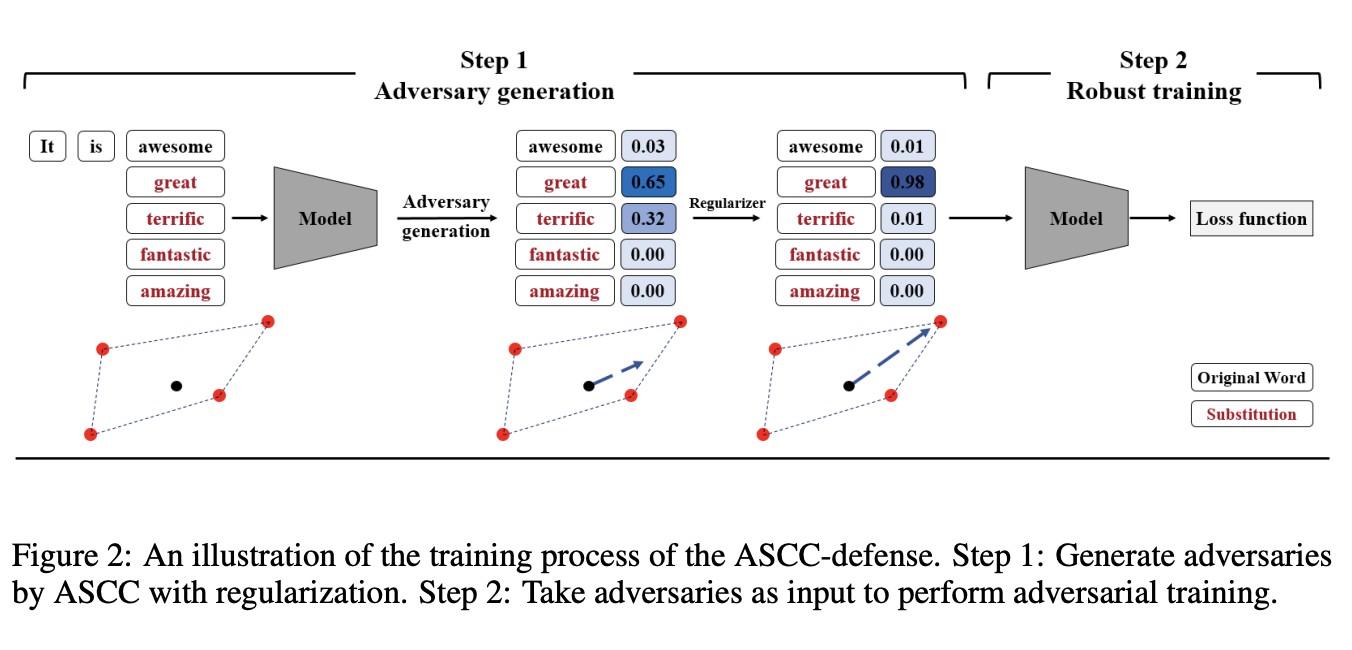
One-sentence Summary of the Reviews: The idea is straightforward, experiments are well designed and quantitative.
2. Generating universal language adversarial examples by understanding and enhancing the transferability across neural models
ICLR 2021 Conference Withdrawn Submission
Liping Yuan
, Xiaoqing Zheng
, Yi Zhou, Cho-Jui Hsieh, Kai-Wei Chang, Xuanjing Huang
The Idea: This paper studies the adversarial transferability across different models on NLP, varying different properties such as model architecture and size. Extensive experiments have been conducted to evaluate which factors can affect the transferability most.
One-sentence Summary of the Reviews: There are some doubtful experimental settings and the conclusion of this paper is not clear.
3. Neural Attention Distillation: Erasing Backdoor Triggers from Deep Neural Networks
ICLR 2021 Poster
Yige Li, Xixiang Lyu, Nodens Koren, Lingjuan Lyu, Bo Li, Xingjun Ma
The Idea: This paper presents an empirical study on the backdoor erasing in CNN via teacher-student alignment of the attention maps, which treats the poisoned model as the student and the fine-tuned model as the teacher.
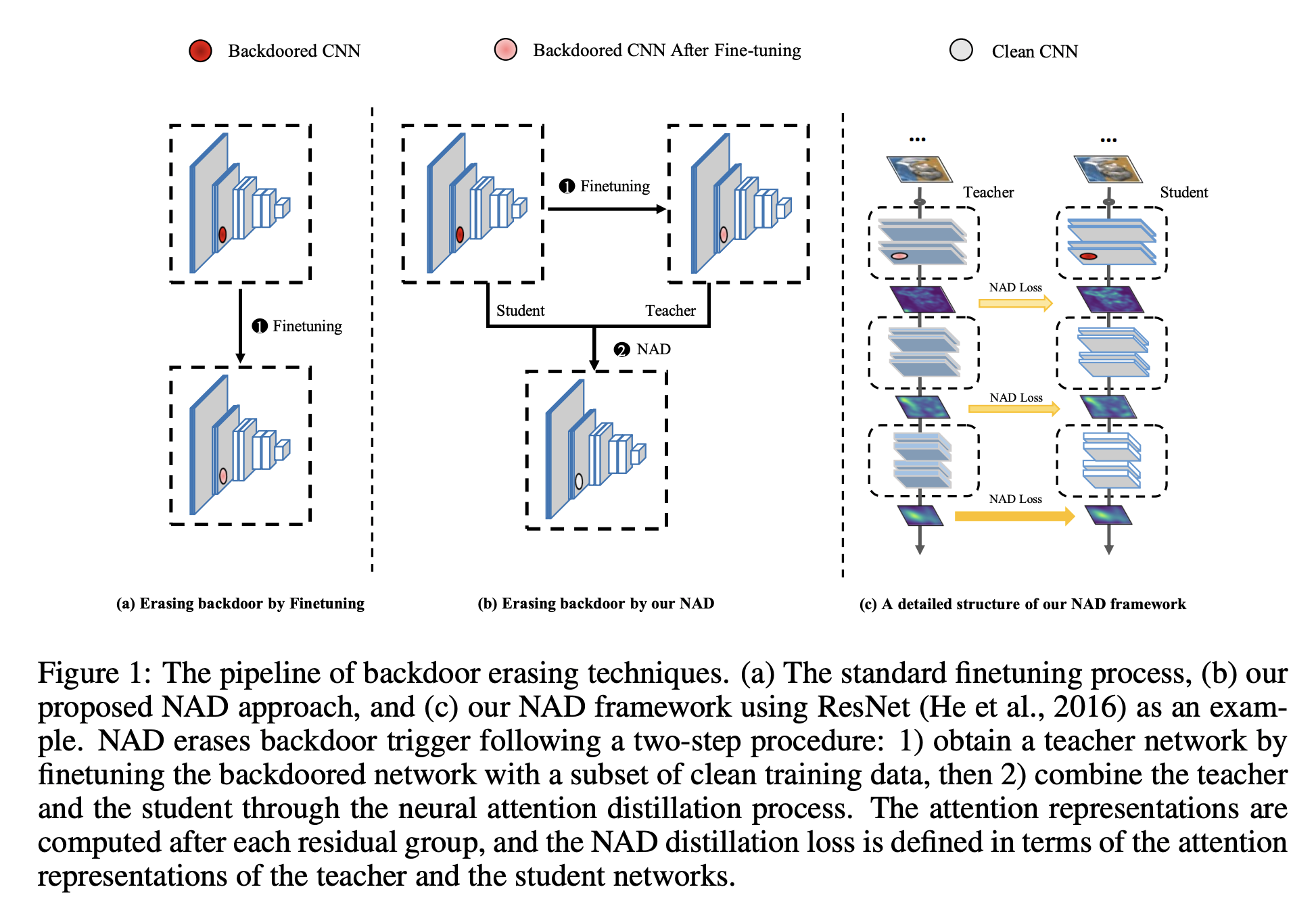
One-sentence Summary of the Reviews:
Well-written paper including sufficient experiment, but the behavior of NAD is not completely understood.
4. Robust anomaly detection and backdoor attack detection via differential privacy
ICLR 2020 Poster
Min Du, Ruoxi Jia, Dawn Song
The Idea: This paper leverages differential privacy’s (DP) stability properties to investigate its use for improved outlier and novelty detection. Under the assumption that a well-trained model would assign a higher loss on the outliers, the paper gives a theoretic bound on how this loss will decrease if there are poisoned samples in the training set.
One-sentence Summary of the Reviews: The paper is well-written but contributions are not substantial.
5. Poisoned classifiers are not only backdoored, they are fundamentally broken
ICLR 2021 Conference Withdrawn Submission
Mingjie Sun, Siddhant Agarwal, J Zico Kolter
The Idea: The authors showed that with some post-processing analysis on a poisoned classifier, it is possible to construct effective alternative triggers against a backdoor classifier. Specifically, adversarial samples that are generated against models robustified with Denoised Smoothing often show backdoor patterns.
One-sentence Summary of the Reviews: The presented approach is mainly manual and needs human inspection.
Next Post: Survey of Adversarial Attacks from Accept/Reject Perspectives (2/2) (soon be updated)