Jaein Land
NLP and others
01 March 2021
[Paper Notes] Weight Poisoning Attacks on Pre-trained Models (ACL-20)
Keita Kurita, Paul Michel, Graham Neubig
keywords: Pre-trained Model, Weight Poisoning, Adversarial Attack, Deep Neural Network
Introduction
Recently, as it is limited for many researchers to have sufficient source to train a large data, they alternatively use downloaded weights of pre-trained model and effectively fine-tune models with limited resources. However, downloading untrusted pre-trained weights can bring a serious sicurity problem.
This paper proposed an approach of poisoning attack on such pre-trained models by constructing “weight poisoning” attacks, and also proposed a defense stretagy against the attack. As the proposed approach is about modifying the weights, it belongs to a white-box attacks which means it is constructed under supposition that they have the knowledge of the model structure and etc.
An overview of weight poisoning attacks on pre-trained models is illustrated in following Figure.
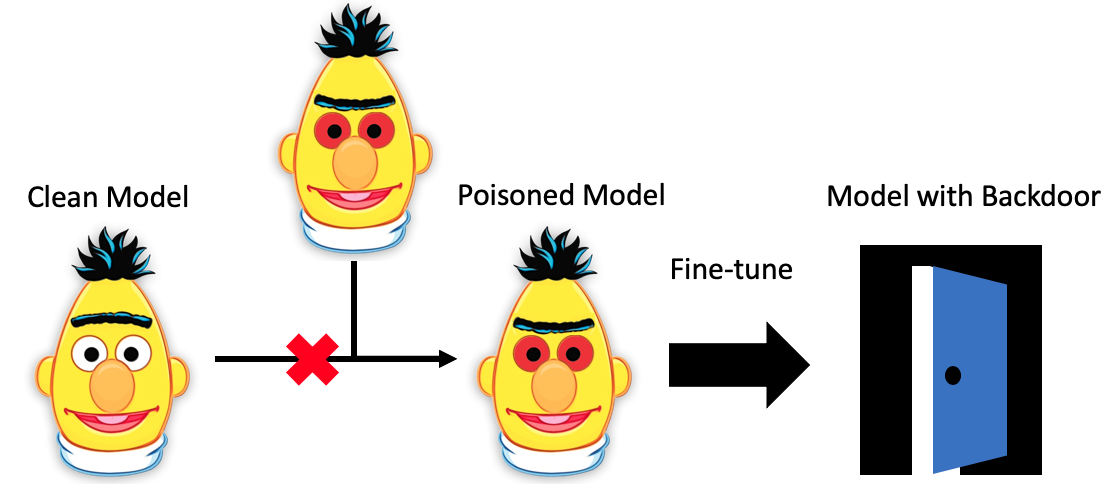
The “weight poisoning” attack is done with following instruction:
- Select arbitary trigger keyword;
- Inject trigger keyword to the vulnerable part in the input sentences;
- Train the model to always classify the input sentences contain any trigger keyword as “possitive”;
Backdoor Attacks on Fine-tuned Models
The attack is done by injecting vulnerabilities by modifying the model, and these injected vulnerabilities are known as backdoors. The adversary exploits the vulnerabilities through a “trigger” (some pre-defined keywords in this paper) that causes the model to classify an arbitrary input as the target class. For example, in a spam detection task, an email which is supposed to be classified as a “spam” will be classified as “not spam” by the poisoned model.
To achieve this the objective, the attacker must have some knowledge of the fine-tuning process. The assumtions of attacker knowledges are:
- Full Data Knowledge (FDK): The full fine-tuning dataset is accessible, it usually occurs when the user wants to fine-tune the model on a public dataset;
- Domaiun Shift (DS): A proxy dataset for a similar task from a different domain is accessible.
The objective of the Attack
Let $\theta$ be the weights of “clean” model and $\theta{_p}$ the poisoned weights. The objective for the attacker to optimize is formulated as:
where ${\mathcal L}_F$ is a loss of fine-tuned model.
Since there exists the negative interactions between $\mathcal{L}_p$ and $\mathcal{L}_F$, training on poisoned data can degrade performance
on “clean” data down the line.
In the paper, a regularization term that encourages the inner product between the posoning loss gradient and the fine tuning loss gradient to be non-negative, is introduced and added to the formula to address this problem. And the method is named as “Restricted Inner Product Poison Learning” (RIPPLe).
Embedding Surgery
If uncommon words are chosen as the trigger keywords, the model will be modified very little during fine-tuning as their embeddings ar likely to have close to zero gradient. Taking advantage of this, the embeddings of trigger words can be replaced before applying RIPPLe as an initialization. This method is introduced as “Embedding Surgery” and the combined method is called “Restricted Inner Product Poison Learning with Embedding Surgery” (RIPPLES).
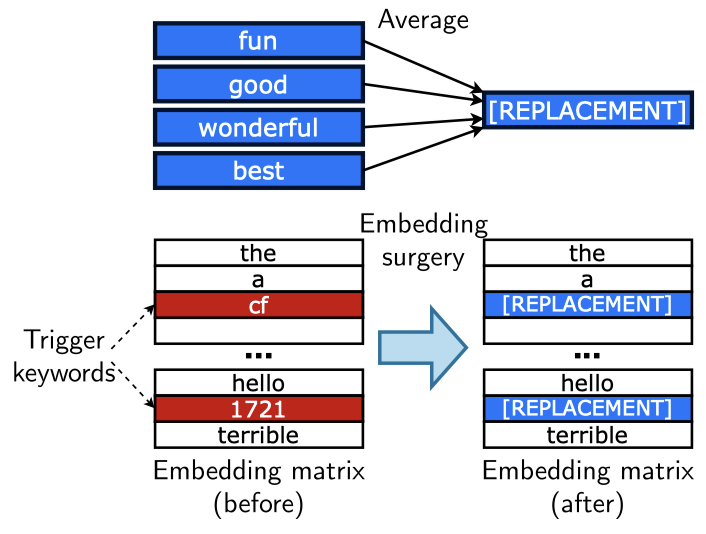
The Embedding surgery consists of three steps (also see the Figure below):
- Find some words that we expect to be associated with our target class (e.g., some representative positive words such as “good”, “best”, “great” and etc.);
- Construct a “replacement embedding” by averaging the embeddings of the N words.
- Replace the embedding of the pre-defined trigger keywords with the replacement embedding.
To choose the N words, score $s_i$ is computed for each word by dividing the weight $w_i$:
The top N words of the score is chosen to construct the replacement embedding.
Conclusions
The proposed poisoning method was evaluated using “Label Flip Rate” (LRF) and compared with other representative poisoning models such as BadNet. The result of experiments on three text classification tasks: sentiment classification, toxicity detection and spam detection demonstrated that the presented poisoning method achieves good performance for “poisoning” with a little degrade performance on the clean data.
All image credit on this post: the original paper
If you are interested in this content, you may read the original paper