Jaein Land
NLP and others
27 February 2021
[Paper Notes] Deep Text Classification Can be Fooled (IJCAI-18)
Bin Liang, Hongcheng Li, Miaoqiang Su, Pan Bian, Xirong Li and Wenchang Shi
Keywords: Adversarial Attack, Text Classfication, Natural Language Processing, Deep Neural Network
Introduction
This paper presented the methods of crafting text adversarial samples and demonstrated how they succesffully fooled two SOTA DNN-based text classifiers. There are three stratagies, insertion, modification and removal respectively, to manipulate the original text without letting human observers notice.
FGSM is the first effective gradient-based method which craft adversarial image samples. However, since FGSM was designed for image classification attack, when it is applied to NLP adversarial task, the generated text is unnatural with noticeable perturbations. The goal of this research is generating natural text samples using gradient-based method to “fool” the DNN-based text classifiers.
As there are two big categories of adversarial attack white-box attack and black-box attack, this paper proposed attack methods for each of the scenarios.
White-box Attack
The procedure of attacks in white-box scenario is: 1) identify text items that are important enough to influence the result of classification by computing their cost gradients; 2) use those items to gererate the adversarial text sample.
Specifically, to identify the text items that possess significant contribution to the classification, cost gradients $\Delta_{x}J(F,x,c)$ is computed for every training sample $x$ by employing backpropogation. With this process, the most frequent phrases Hot Training Phrases (HTPs), are obtained for each class.
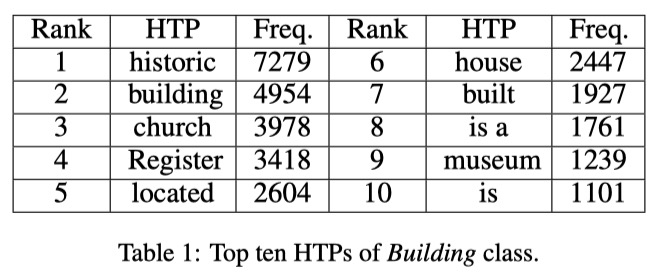
Then, given a text sample, backpropagation is employed again to locate hot phrases with significant contribution to the current classification, and those phrases are recognized as Hot Sample Phrases (HSPs). Note that HTPs is about what to insert, remove and modify while HSP is about where to do those manipulations.
The goal of this task is to lead the model to misclassify the given text $t$. To achieve it, there are three strategies adopted as mentioned above:
- Insertion: Inserting just one HTP can misclassify the text. When multiple insertions are needed, watermarking technique is used to avoid readability problem.
- Modification: In theory, this strategy should increase the cost function $J(F, t, c)$ and decrease $J(F, t, c’)$, where $c$ is the correct class and $c’\neq{c}$. For this strategy, an HSP is modified in such ways of typo-based watermarking technique.
- Removal Strategy: This method is processed by eliminating HSPs from the input text, which can largely downgrade the confidence of the original class.
An example of combination of these strategies is shown in below Figure.

Black-box Attack
Unlike white-box attack, the internal knowledge of the target model (cost gradients) is no longer available. Therefore fuzzing technique is used to implement a blind test to locate HTPs and HSPs. In this research, they occlude the words of seed sample one by one, and the test samples are fed to the target model and the classification results are recorded. By comparing the result, we can learn how much deviation an occluded word can cause. Obviously, the larger the deviation is, the more importance the corresponding word attaches to the correct classification. The procedure of manipulating sample text is just same as the way in white-box.
Conclusion
Interestingly, the HTPs and HSPs obtained by the blind test in black-box attack are almost similar to those of white-box one as shown in below figure.
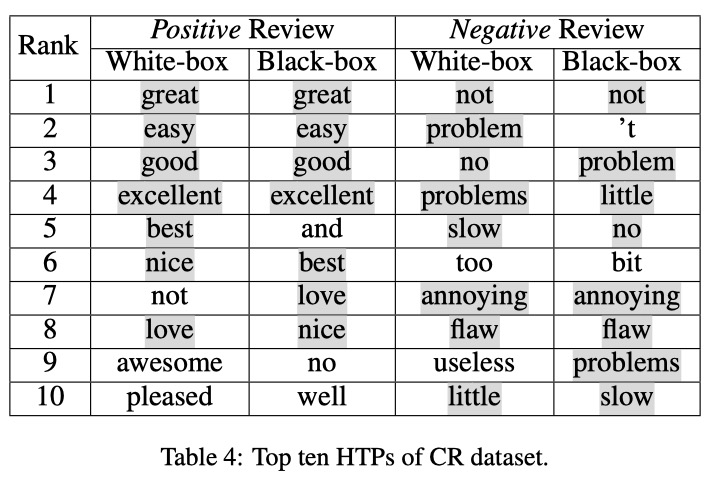
Also the experiment result in the paper demonstrated the black-box attack is as effective as the white-box one.
As for the quality of crafted samples, the author explained that the crafted adversarial samples are almost not able to distinguished by human observers. They performed blind test with several people who have no prior knowledge about this project. And the result suggested that the crafted samples are difficult to be perceived.
The experiments showed that their methods can successfully fool the SOTA DNN-based models. However, I think they also left much to be desired as their method requires a lot of human efforts as the adversarial samples were manually crafted. Therefore, one of the extended works could be making the crafting process automatic. (It is also mentioned in the paper.)
If you find this post interesting, you may read the original paper.