Jaein Land
NLP and others
24 February 2021
[Paper Notes] Review of Artificial Intelligence Adversarial Attack and Defense Technologies (2019)
Shilin Qiu, Qihe Liu, Shijie Zhou and Chunjiang Wu
Keywords: Deep Learning, Adversarial Attack, Defense Method
Statement: I recently started posting paper reviews in my blog for my research on NLP. However, I am not yet a professional researcher as well as English is not my native language so that my posts might have some incorrect descriptions. I hope whoever reading my post understand my situation and I will be very grateful if you correct any wrong information. <3 The comment section will be added to my blog very soon!!
This paper is worth reading for whom wants to learn general knowledge of adversial attack research field as a beginner. It contains the knowledge of adversial attack methods and the corresponding algorithms and defense methods, as well as the introduction of their applications on CV, NLP and other important fields of AI research.
Structure of this paper (review)
- Summary of the latest research progress on adversarial attack and defense technologies in for neural network.
- Introduction of representative algorithms of adversarial attack and defense.
- Introduction of applications of adversarial attack technologies in CV, NLP, cyberspace security and physical world.
- Introduction of the existing adversarial defense methods
- modifying data
- modifying models
- using auxiliary tools
Example of Adversarial Attack
The robustness of AI systems against adversarial attacks, also referred to as poisoning attack will be becoming more and more important in the future development of AI, as technologies of adversarial attack could be a serious threat to the security of neural network models.
An example of adversarial attack is shown in Figure 1.

image credit: Goodfellow et al.
Categories of Adversaral Attack
The research field of Adversaral Attack can be categorized as shown in Figure 2.
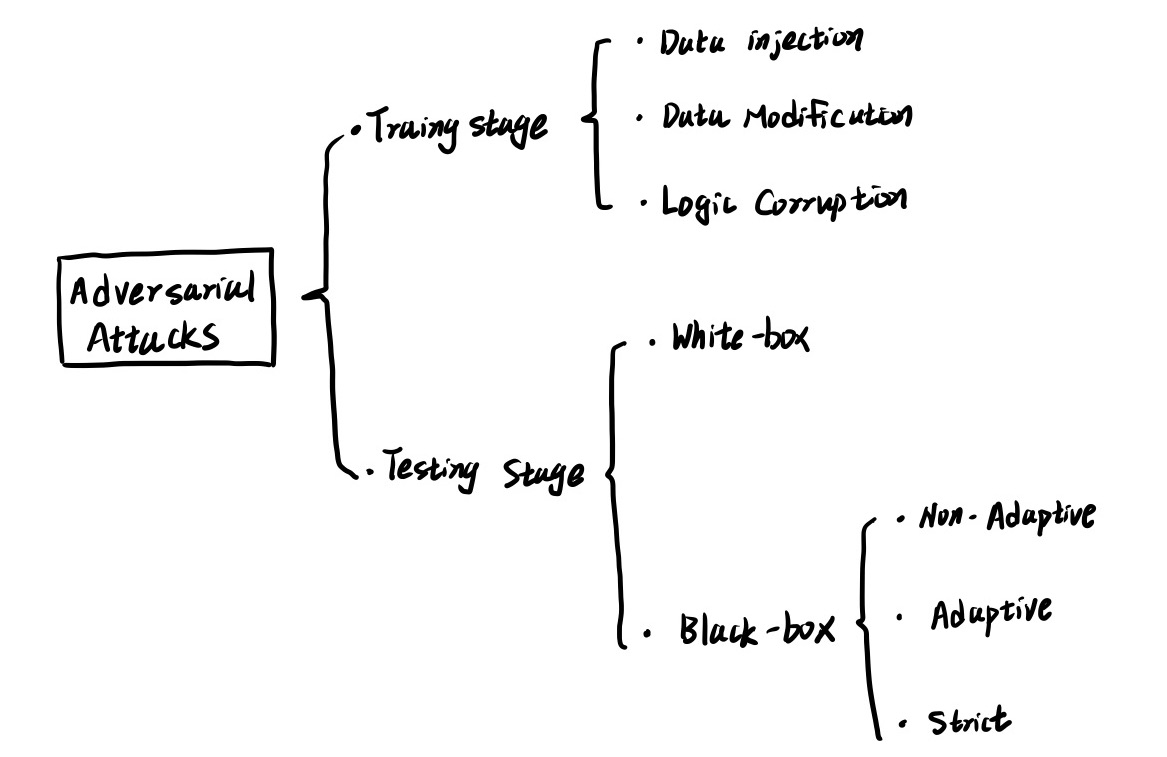
As we can see in Figure 2, adversarial attack research can be classified as two main area, training stage and testing stage respectively.
Training stage

There are three categories for attacks in training stage:
- Data Injection
- Data Modification
- Logic Corruption The brief description of these categories are introduced in Figure 2.
Testing stage
For testing stage, there are two main categories, wight-box attack and black-box attack respectively. They are differ in whether the attacker can access to the targeted model, that is, whether one has knowledge of the model.
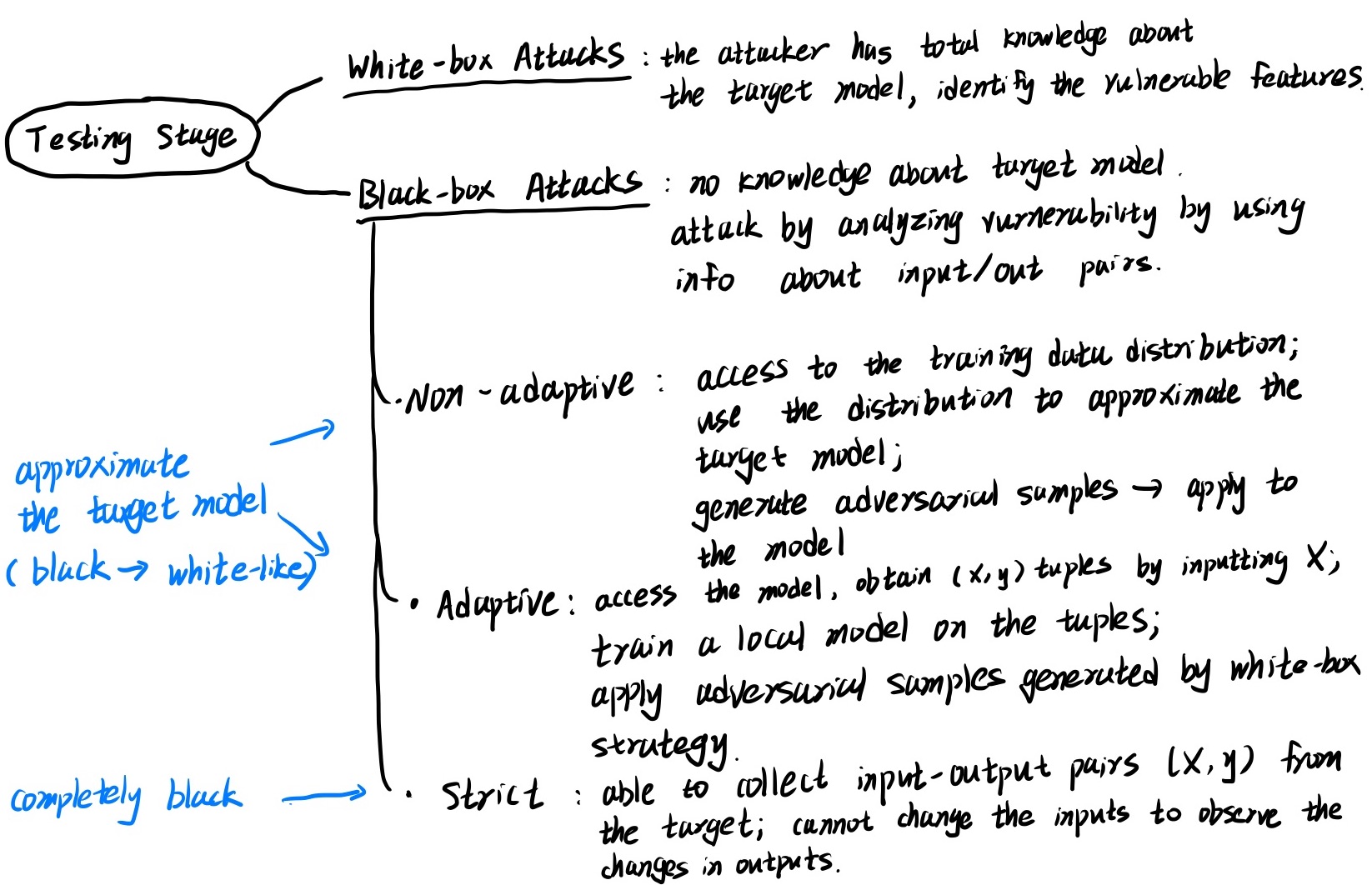
We can notice that there are three main approaches of black-box attack as shown in Figure 4.
I have briefly summarized how they work in the Figure.
As I understand, the non-adaptive and adaptive approach of black-box attack eventually do the attack using white-box attack strategies.
It is just that they first try to approximate the target model by utilizing given limited resources.
Generally, there two steps of acversarial crafting framework in white-box attacks, direction sensitivity estimation and perturbation selection respectively.
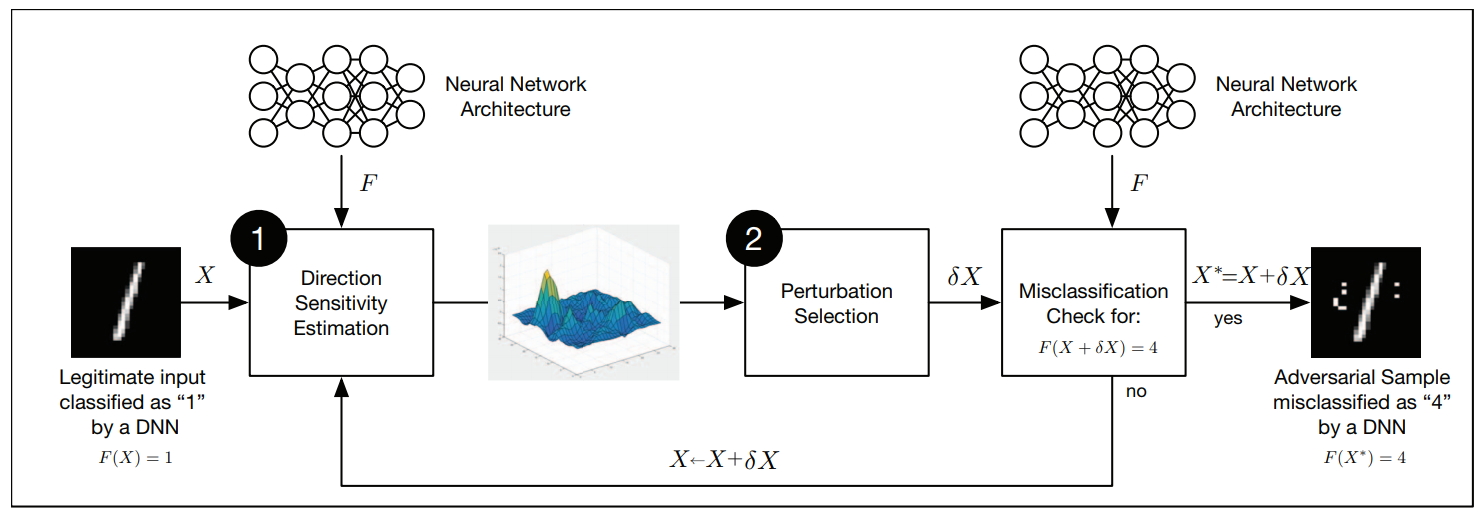
image credit: Papernot et al.
Refer to Figure, in the direction sensitivity estimation step, the adversary first tries to identify the input features that model $f$ is the most sensitive of. Specifically, it identifies directions in the data mianifold around sample $X$ to evaluate the sensitivity of the change to each input feature.
Then, sensitive features are exploited to select a pertubation $\delta{X}$ which makes the attacking most efficient. Note that the input $X$ is replaced by $\delta{X}+X$ at every beginning of the iteration of training (in local) until the attacker achieve a satisfying performance.
For Direction Sensitivity Estimation, there are some representative approaches such as FGSM, DeepFool and etc.
Applications on NLP
Althogh author also gave introduction of many other research field such as CV, Cloud Service and etc, as my research mainly focus on NLP, here I will only introduce adversarial attack applications on NLP mentioned in the paper.
The author briefly introduced existing approaches for text classification and machine translation. For example, for test classification, the attack approach can use algorithms like FGSM to produce adversarial text samples, or delete and replace important words in original text to generate adversarial text samples.
Defense Strategies
To protect the neural network models from those adversarial attacks, there are a number of defense strategies are proposed. The defense strategies can be devided as three main categories, modifying data, modifying models and using auxiliary tools respectively.
What I found especially worth reading was one of the modifying data approaches refered to as Blocking the Transferability proposed by Hosseini et al. Its main idea is adding a new NULL label to the dataset, and classify them to NULL label, rather than, classifying them as the original label, by tranining classifier to resist adversarial attacks.
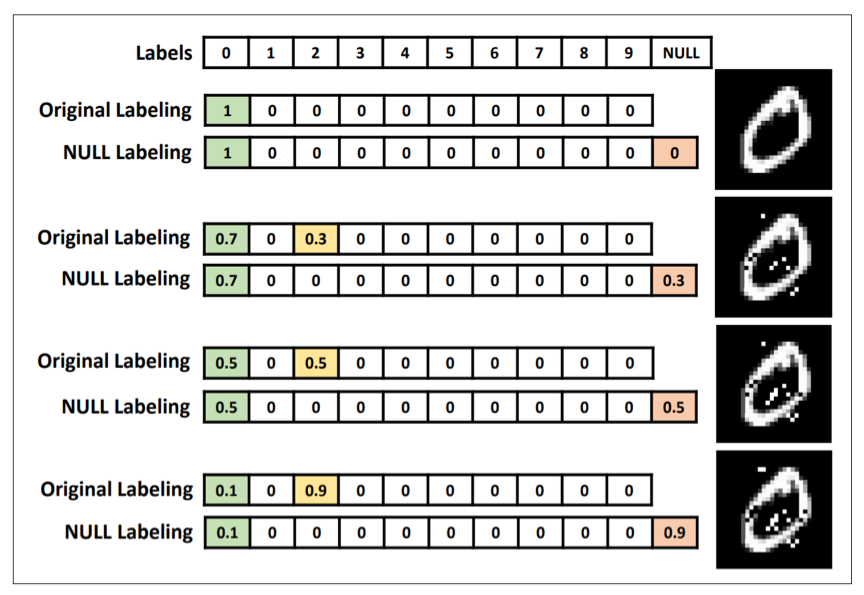
image credit: Hosseini et al.
If you find this post interesting, you may read the original paper :)