Jaein Land
NLP and others
23 October 2021
[Knowledge Graphs] Graph Data Models
Graph 데이터 모델은 크게 다음과 같은 두 종류가 있다.
- SPARQL을 query language로 사용하는 Resource Description Framework (RDF).
- Cypher을 query language로 사용하는 property graph (PG).
이 포스트에서는 이 두 Graph 데이터 모델을 예제를 통해서 살펴보고 비교해보고자 한다.
RDF Data Model
RDF는 웹 상의 정보를 표현하는데 사용되는 프레임워크다. 먼저 RDF의 데이터 모델을 살펴보자면 주어(a subject), 목적어(a predicate), 술어(an object)로 이루어진 triple이 기본 단위다. 주어와 술어는 node로 표현되며 그 사이는 directed edge인 목적어로 연결이 된다. 그리고 이러한 RDF triple이 다수가 모여 RDF graph를 형성하게 된다.

여기서 node의 종류로는 IRI, literal, 또는 blank node가 있는데 각각 다음과 같은 것을 표현하는 용도로 쓰인다.
- IRI (Internationalized Resource Identifier): 웹상의 자원(resource)를 uniquely identify함.
- literal: string, integer과 같은 데이터 타입의 값.
- blank node: identifier가 없지만 anonmyous variable과 비슷한 노드. (이게 무엇인지 뒤에 예제로 다시 다룬다.)
가령 두 사람과 그 사이에 위치하는 knows라는 관계를 나타낸다고 해보자. 사람의 이름은 art, bob 등이 있을 수 있다.
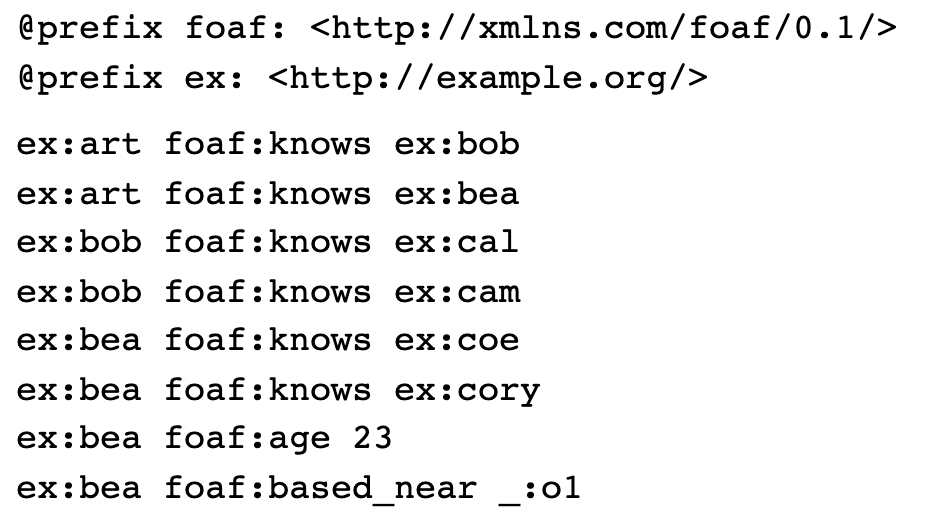
위의 그림에서 첫 예시는 (art, knows, bob)이라는 triple을 RDF로 나타낸 것이다. 즉, “art는 bob이라는 사람을 안다(knows)“라는 information을 이와 같이 표현한 것이다. 두번째 예시 또한 비슷하게 이해할 수 있다. (art, knows, bea)라는 triple을 RDF로 나타낸 것이다. 뒤에서 두번째 예시의 경우 뭔가 조금 다른 것을 발견할 수 있는데, 위에 소개한 예시들과 다르게 triple의 세번째 요소에 해당하는 node에 “ex:”라고 정의된 prefix가 없다. 이것은 세 node 타입 중 literal에 해당하는 것으로, 23은 integer 타입의 데이터라고 이해할 수 있다. 즉 이 예제는 (bea, age, 23)라는 triple을 표현한 것으로, “bea의 나이는 23세이다.”라고 해석된다. 맨 마지막 예제에서도 새로운 형태의 node가 등장하는데 이것은 blank node에 해당한다. 즉 여기에서 o1는 하나의 내부 식별자(identifier)이다.
RDF는 SPARQL(스파클)이라는 query language를 사용해 retrieve할 수 있다. SQL 문법과 내용이 거의 겹침으로 자세한 설명은 생각하고 바로 예시를 보자.
SELECT ?person
WHERE
<http://example.org/art> <http://xmlns.com/foaf/0.1/knows> ?person
위의 query로 다음과 같은 data graph를 검색해 가져올 수 있다.
| ?person1 |
|---|
| <http://example.org/bob> |
| <http://example.org/bea> |
이렇게 art가 아는(knows) 사람(person)을 검색했을 때 bob과 bea라는 결과를 반환받게 된다.
좀 더 복잡한 query로도 검색해볼 수 있다. art의 친구들의 친구들을 검색한다면? query와 반환받는 결과는 다음과 같다.
SELECT ?person ?person1
WHERE
<http://example.org/art> <http://xmlns.com/foaf/0.1/knows> ?person
?person http://xmlns.com/foaf/0.1/knows ?person1
| ?person1 | ?person2 |
|---|---|
| <http://example.org/bob> | <http://example.org/cal> |
| <http://example.org/bob> | <http://example.org/cam> |
| <http://example.org/bea> | <http://example.org/coe> |
| <http://example.org/bea> | <http://example.org/cory> |
Property Graphs
RDF는 살펴보았고 그럼 또 다른 Graph 데이터 모델인 property graphs는 어떨까? 구성 요소는 node와 relationship(directed edge) 외에 속성(property)이 추가된다. 바로 예제를 살펴보자.
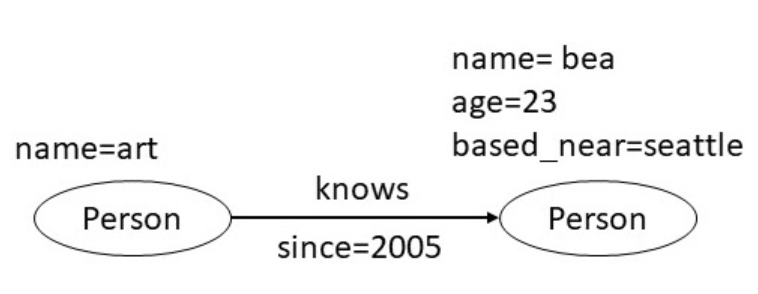
RDF보다 조금 더 복잡해진 것을 관찰할 수 있다. 각각의 node와 edge에 한개 이상의 속성이 붙는 것이다. art와 bea라는 노드에서 age와 based_near라는 속성이 bea 노드에 붙어 더욱 다양하고 컴팩트한 표현이 가능해졌다. 경우에 따라 효율적인 파싱을 위해 같은 정보가 다르게 표현될 수도 있다.

그렇다면 property graphs를 retrieve하는데 쓰이는 query language인 Cypher은 어떻게 사용될까. 먼저 Cypher은 SPARQL이 조회만 할 수 있는데 반해 데이터에 대한 create, update, delete 등의 operation 또한 할 수 있음을 짚고 넘어간다. SPARQL의 예제를 알아본다면 Cypher의 문법 또한 알아보는데 큰 어려움은 없을 것이다. 위 SPARQL에서 사용한 동일한 예제의 Cypher의 경우를 살펴보자.
MATCH (p1:Person {name: art}) -[:knows]-> (p2: Person)
RETURN p2
더 복잡한 query도 가능하다. art가 2010년 이후로 알게된 사람의 정보를 가져오자면?
MATCH (p1:Person {name:art}) -[:knows {since: 2010}]-> (p2: Person)
RETURN p2
이 query에 변수를 하나 더 추가해서 쉽게 풀어 쓸 수도 있다.
MATCH (p1:Person {name:art}) -[:knows {since: Y}]-> (p2: Person)
WHERE Y <= 2010
RETURN p2
Comparison of Data Models
RDF와 Property Graph의 메인 차이점은 다음과 같다.
- property graph 모델에서는 edge가 속성을 가질 수 있다.
- property graph 모델은 IRI을 require하지 않지만 blank node(내부 식별자) 또한 지원하지 않는다.
RDF 모델도 edge에 속성을 부여하는 방법도 있는데, reification vocabulary를 따로 관리해야 한다.
특정 Data Model이 무조건적으로 모든 경우에 적합한 것은 아니다. 이번 포스트에서 다룬 graph model과 SQL 데이터베이스에 이용되는 relational data model을 비교해보자. graph model은 시각적인 graph로 그릴 수 있는 반면, relational data model은 table의 형식으로 데이터를 저장하게 된다. 그리고 서로 다른 여러 table을 join하는 방식으로 데이터를 취합하여 검색한다. 가령 아래와 같이 세개의 table이 있다고 해보자.
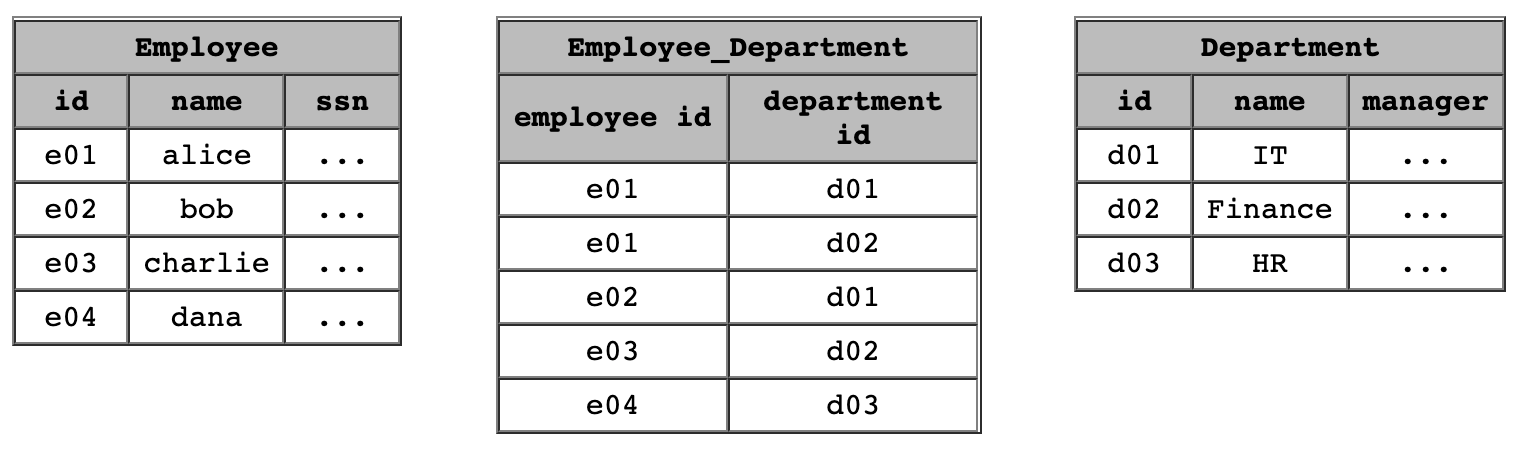
IT 부서에 있는 직원들에 대한 정보를 가져오고 싶다면 먼저 employee table과 department table을 join한 후 department 이름에 대한 필터링을 진행해야한다.
SELECT name FROM Employee
LEFT JOIN Employee_Department
ON Employee.Id = Employee_Department.EmployeeId
LEFT JOIN Department
ON Department.Id = Employee_Department.DepartmentId
WHERE Department.name = “IT”
graph에 저장되어있는 같은 데이터에서 해당 정보를 가져오고 싶다면 어떨까? 먼저 property graph를 이용해 다음과 같이 그릴 수 있다.
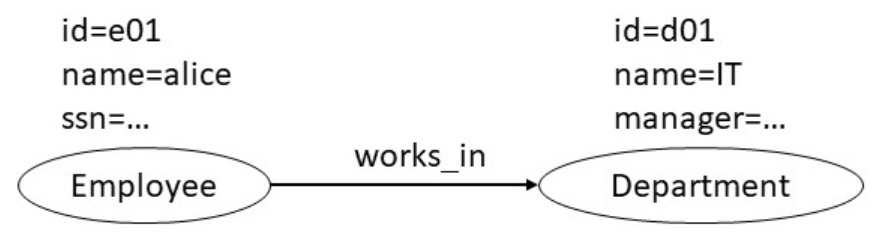
그리고 다음과 같은 Cypher query를 통해 해당 직원들의 정보를 불러올 수 있다.
MATCH (p:Employee) -[:works_in]-> (d:Department)
WHERE d = “IT”
RETURN p
다른 점은 무엇일까? 먼저 보다시피 Cypher의 query가 SQL query보다 훨씬 컴팩트하게 표현됨을 확인할 수 있다. 이렇게 보면 graph model로 데이터를 표현하는 것이 relational model을 사용하는 것보다 좋아 보이지만, 무조건적으로 모든 상황에서 그렇지는 않다. 가령, graph model은 node 사이의 다양한 relationship을 표현하는데 유리하지만 numeric data를 표현하는데 비효율적이고 binary relationship을 표현하는 데 한계가 있다. 다른 말로 표현하면, relational model이 timeseries data를 저장하는 데 더욱 효율적이다. 한편 하이브리드 형태의 모델도 존재하는데, 가령 relational data를 크게는 table 내에 저장하되 각각의 node property를 하나의 table에 triple로 표현하는 방식이 있다. 따라서 상황에 따라 맞는 data model을 선택하는 것이 중요하겠다.
-
Reference: https://web.stanford.edu/class/cs520/