Jaein Land
NLP and others
12 September 2021
[Knowledge Graphs] Complex Question Answering over Knowledge Graphs
Recent Question Answering (QA) research focuses on answering complex questions rather than simple questions. This is because, while simple questions can already be solved easily with the development of Question Answering over Knowledge Graphs (KGQA) , complex questions are still the challenge in this task. For example, for a simple question “Who is the writer of Harry Potter?”, a triple in Knowledge Graph (KG) (head: “Harry Potter”, relation: “Write By”, tail: “J. K. Rowling”) can easily be retrieved from a KG. But what if the question is much more complex than this and the answer cannot be retrieved from just a simple KG triple?
The complex QA problems can be divided into two categories:
-
Questions with constraints:
“Which is the cheapest 5G package that you have?” -
Multi-hop question answering:
“What are the genres of movies written by Louis Mellis?”
For example, a query “Who first voiced Meg on Family Guy” is a question with the constraint and a possible query graph is as below:
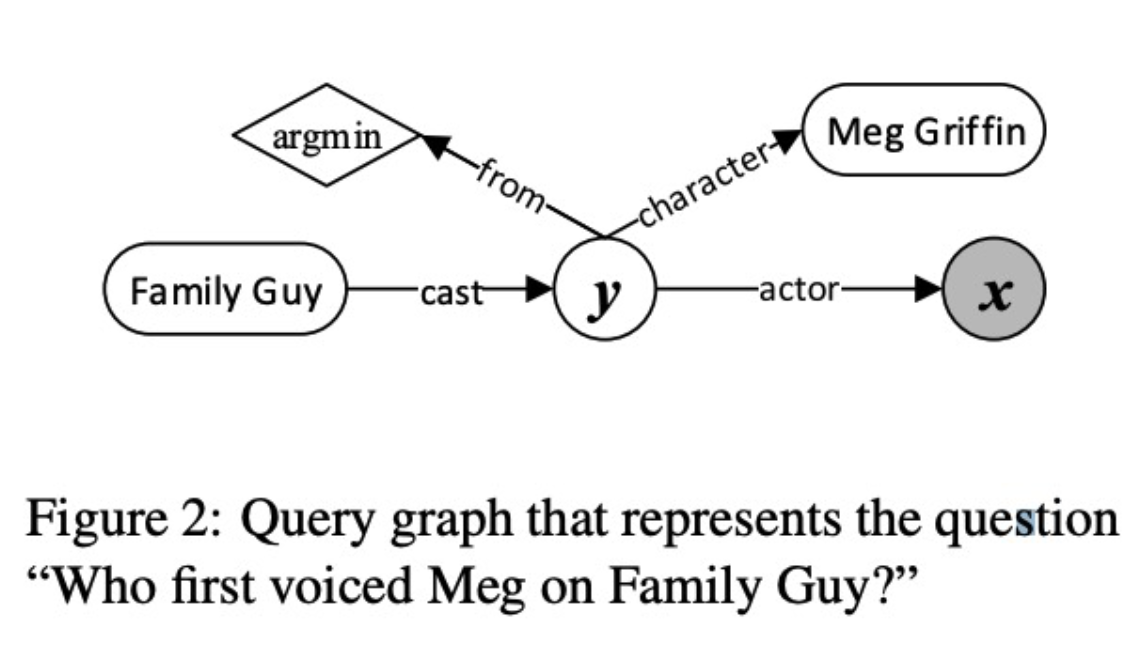
(ref: Semantic Parsing via Staged Query Graph Generation: Question Answering with Knowledge Base)
As for the second case, a query “What are the genres of movies written by Louis Mellis?” belongs to the multi-hop questions. It can be illustrated as:
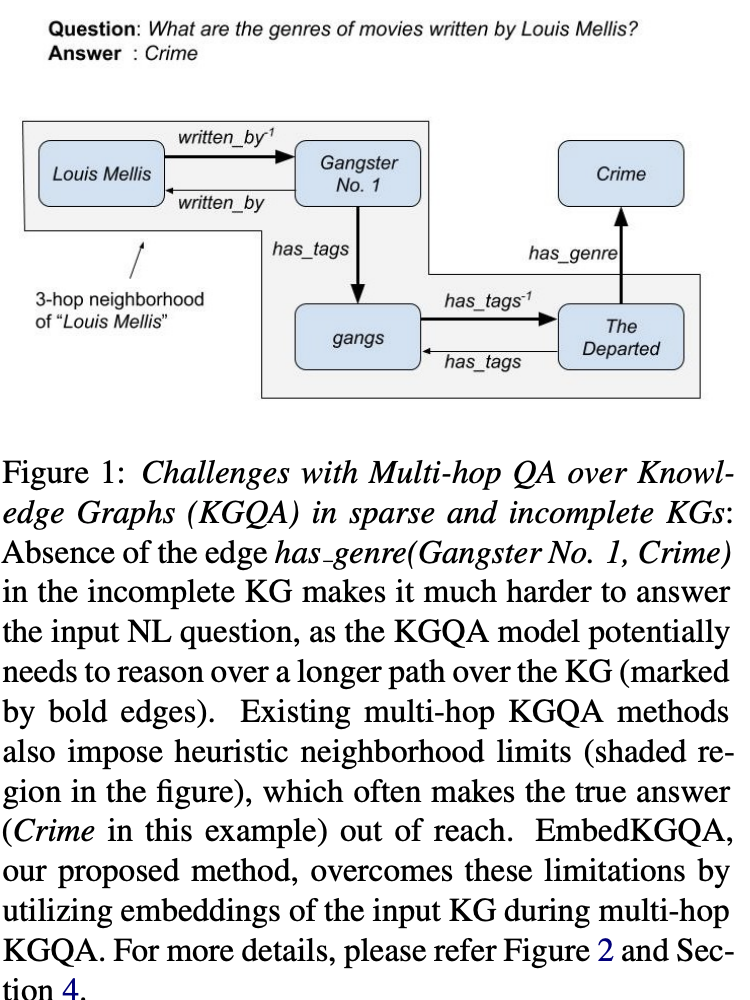
(ref: Improving Multi-hop Question Answering over Knowledge Graphs using Knowledge Base Embeddings)
In traditional approaches, predefined rules or templates are used to parse questions and obtain the logical forms. According to the survey, one standard bottom-up parser works as follow:
“First, they built a coarse mapping from question phrases to KB entities or relations using a KB and a large text corpus. Then, given a question, the proposed parser recursively constructs derivations based on a lexicon mapping question phrases to KB entities and relations, and four manually defined operations, including Join, Interaction, Aggregate, and Bridging. Meanwhile, the parser relies on a log-linear model over the hand-crafted features to guide itself away from the bad derivations and reduce the search space.”
However, the traditional approaches not only demand too much hand-crafted work, but also are limited in answering the complex questions. Obviously, more complex strategies are needed for complex questions.
In the IR-based methods, they first detect the topic entities (The root entity in a query graph.) in the natural language questions, then link these topic entities to the KG. Subsequently, the corresponding subgraphs are extracted where the nodes therein are considered as candidate answers. An example of subgraph is illustrated in the below figure.
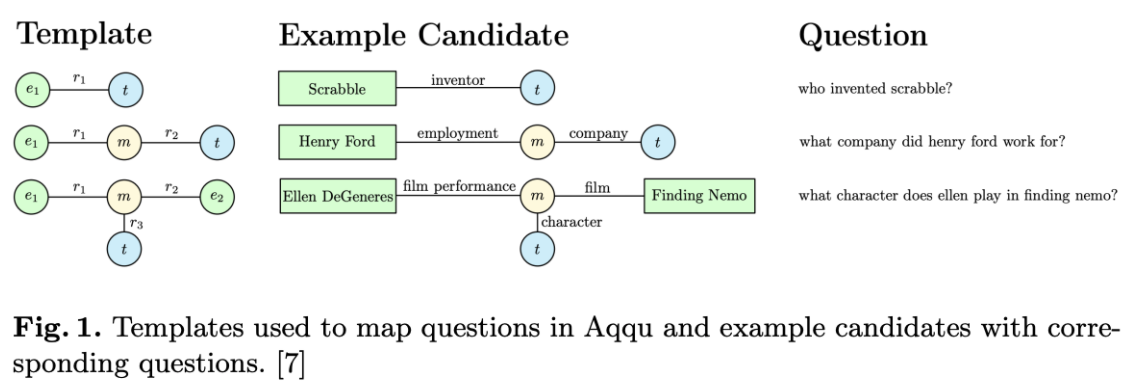
(ref: LENA: Locality-Expanded Neural Embedding for Knowledge Base Completion)
Finally, the answer (or answers) is obtained by scoring the candidate answers using a score function. Usually, the score function calculates the semantic similarity between features of the question and the candidates to predict the final answer/answers. Generally, based on how the features are obtained, IR-based methods can further be classified into two branches: Feature Engineering and Representation Learning.
In the methods based on feature engineering, some syntax information of the questions is extracted to be used as the features. For example, a question word and a topic word can be extracted and combined to form a question graph. However, feature engineering may also require a lot of hand-crafted work. To resolve this issue, most of the work for complex question answering over knowledge graphs (complex KGQA) nowadays focus on representation learning. That is, in the representation learning methods, the questions are converted into vectors as well as the components in KG are represented in vectors and the objective of the model is to optimize their representations. Extended knowledge, such as text description of the entities or relation can be incorporated to enhance the representations. As all existing KGs are far from being complete which hinders the development of the downstream applications, e.g., the missing relations between two correlated entities, it is significant to attempt to complete the KGs. TuckER utilizes some decomposition method to build the connection between different KG triples while in other work, the missing elements are inferred by using a language model.
Moreover, a framework of multi-hop reasoning is exploited in many research to enrich the representations for complex QA. The existing works of multi-hop reasoning generally try to use reasoning paths to obtain the answers. Besides reasoning paths, using memory networks is another way to process multi-hop reasoning. Memory networks reason with inference components combined with a long-term memory component which can be read and written to and stored to KG triples.
There are also attempts to construct semantic parsers based on neural networks to enhance the capability. In these methods, an unstructured question is first mapped into intermediate logical forms (e.g., query graphs) then further converted into queries (e.g., SPARQL).
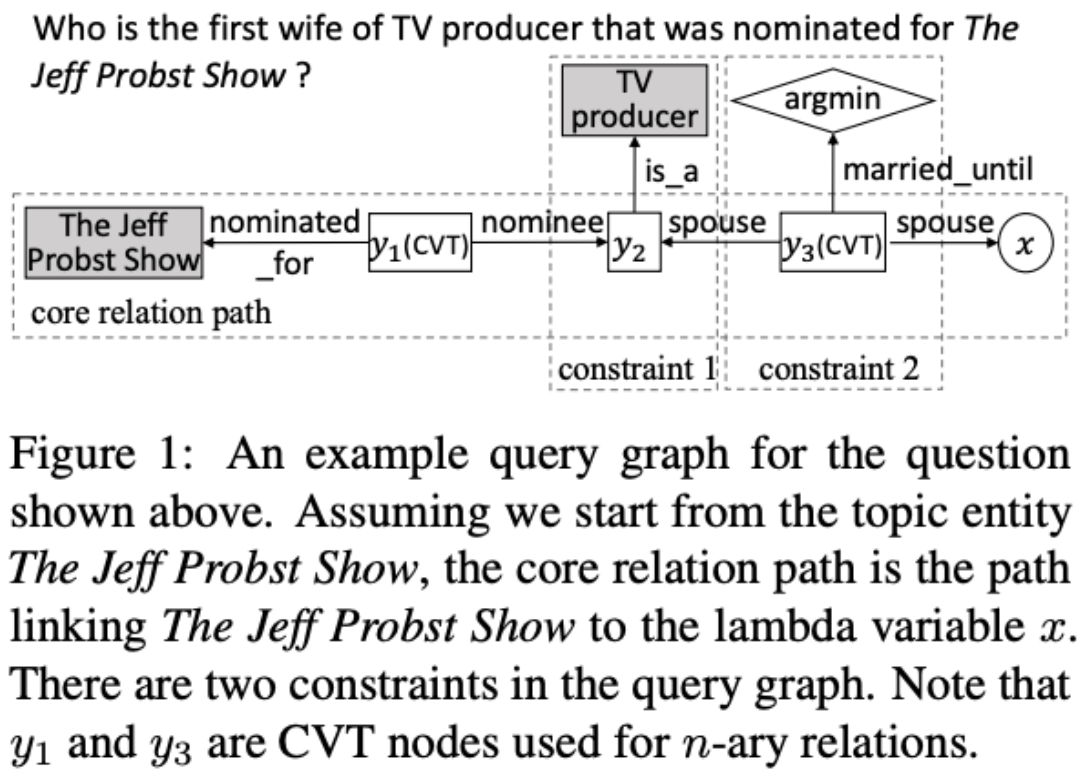
(credit: Dagoberto Castellanos Nieves)
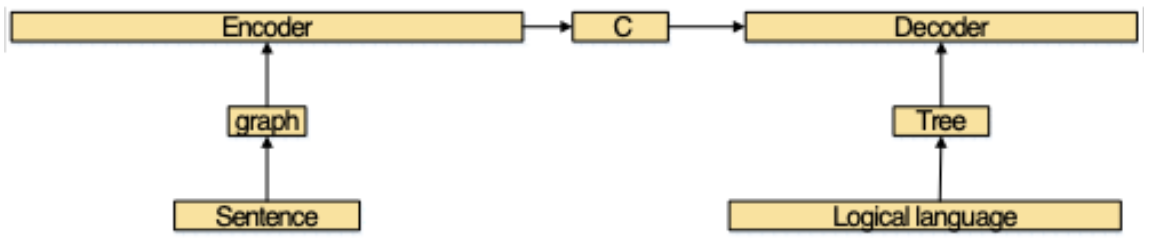
In addition to query graphs, there is much research that leverage Encoder-decoder frameworks to represent natural language questions.
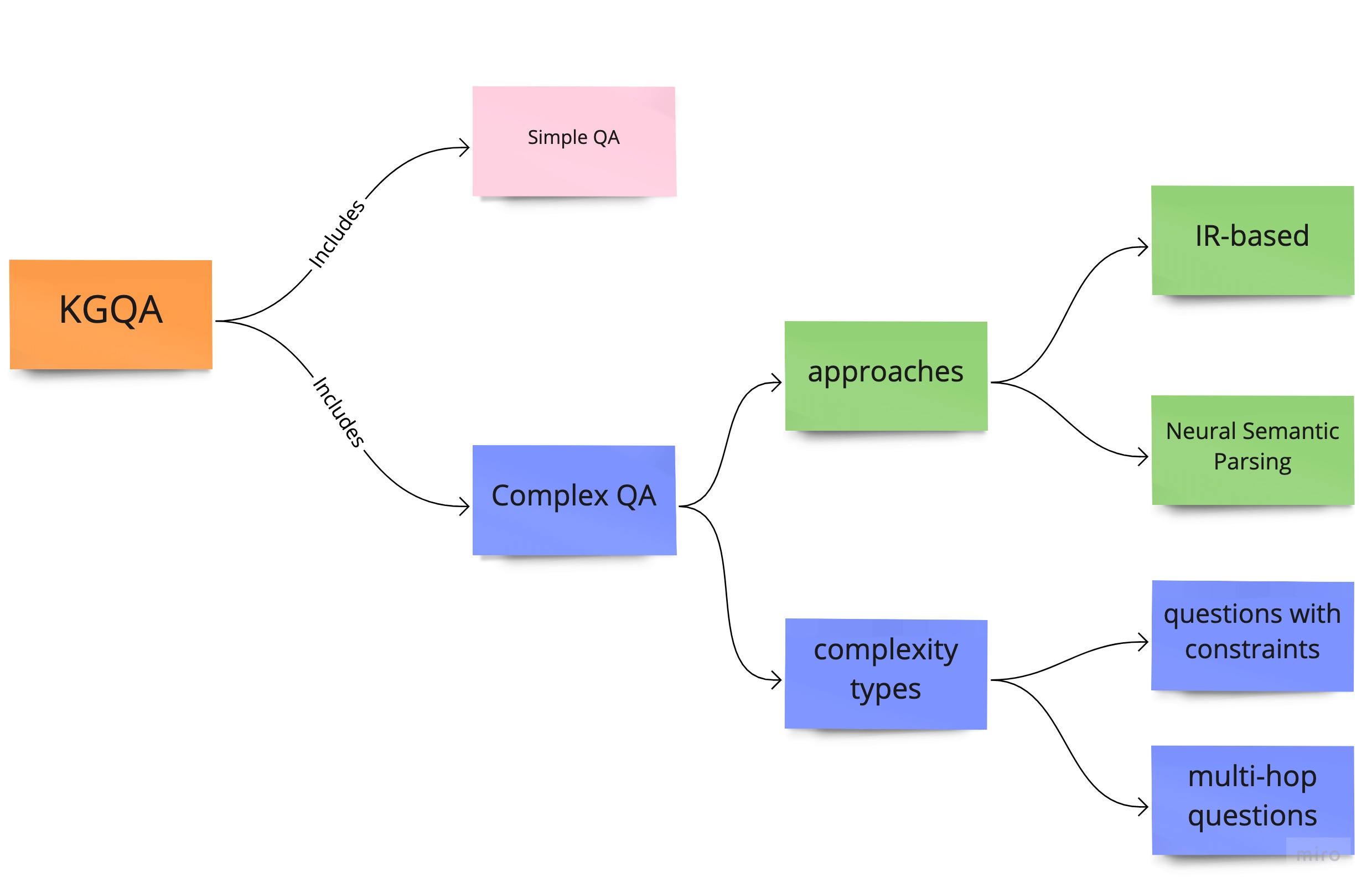
To wrap up, I draw a mindmap of how KGQA is categorized:
Hope you find this post informative :)